Architecture
GreptimeDB uses a compute-storage separation architecture where durable data persists in object storage and compute nodes scale independently. This model supports elastic scaling and lower operational cost compared to architectures that rely on local disks as primary storage.
High-level Architecture
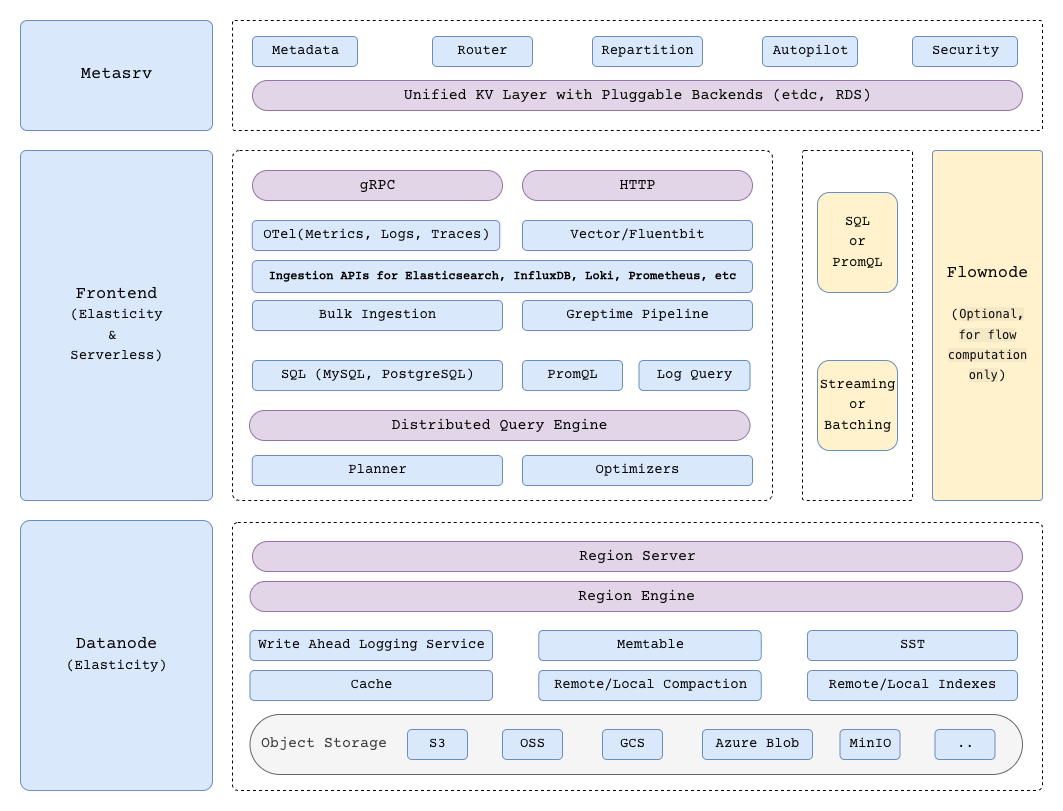
Components
GreptimeDB has three core components in distributed mode, and one optional component for flow computation:
- Metasrv: Metadata and routing control plane. It manages catalogs/schemas/tables/regions, coordinates scheduling, and serves routing data to other nodes.
- Frontend: Stateless access layer. It accepts client protocols, authenticates requests, plans/distributes queries, and routes writes/reads using metadata from Metasrv.
- Datanode: Storage and execution layer. It stores table regions, handles reads/writes, persists WAL, and flushes data files to object storage.
- Flownode (optional): Streaming/continuous computation runtime for Flow Computation. It is used when flow workloads run as a separate service in distributed deployments.
In standalone mode, you run one GreptimeDB process instead of managing these services separately.
How it works
Write path
- A client sends write requests to Frontend via supported protocols.
- Frontend resolves table and region routes from Metasrv metadata (with cache refresh when needed).
- Frontend splits and forwards requests to target Datanodes.
- Datanode writes data to memory and WAL, then eventually flushes immutable data files to object storage.
Query path
- A client sends SQL, PromQL, log, or trace queries to Frontend.
- Frontend creates a distributed plan and dispatches sub-queries to relevant Datanodes.
- Datanodes execute sub-queries on regions and return partial results.
- Frontend merges the results and returns the final response.
Flow path (optional)
When flow computation is enabled, Flownode runs continuous tasks that read source table changes and write computed results to sink tables. For details, see Flow Computation.
For implementation details, see Contributor Guide.